Titanic 데이터 셋 처리하기
데이터셋 링크 https://www.kaggle.com/c/titanic/
구조
| Variable | Definition | key |
|---|---|---|
| survival | survival | 0 = No, 1 = Yes |
| pclass | Ticket class | 1 = 1st, 2 = 2nd, 3 = 3rd |
| sex | Sex | |
| Age | Age in years | |
| sibsp | # of siblings / spouses aboard the Titanic | |
| parch | # of parents / children aboard the Titanic | |
| ticket | Ticket number | |
| fare | Passenger fare | |
| cabin | Cabin number | |
| embarked | Port of Embarkation | C = Cherbourg, Q = Queenstown, S = Southampton |
데이터셋 살펴보기
1
2
3
4
5
6
7
import numpy as np
import pandas as pd
train_df = pd.read_csv('datasets/train.csv')
test_df = pd.read_csv('datasets/test.csv')
# 그냥 두개 합친다. 나중에 전처리 후 나누기
train_df = pd.concat([train_df, test_df])
train_df.head()

데이터 개수와 타입
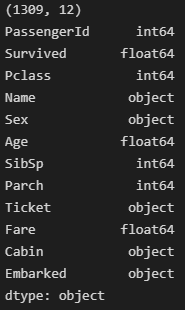
데이터 전처리
결측값 확인
1
print(train_df.isnull().sum(axis=0))
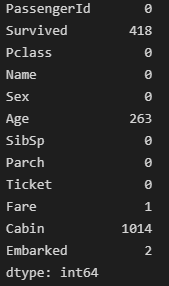
비어있는 Survived와 Age는 중앙값으로 대체하고, 나머지 결측값 행 드랍
1
2
3
train_df['Survived'] = train_df['Survived'].fillna(train_df['Survived'].median())
train_df['Age'] = train_df['Age'].fillna(train_df['Age'].median())
train_df.dropna(axis=0, inplace=True)
문자 -> 숫자
성별은 문자로 되어있으므로 숫자로 바꾼다.
1
2
train_df['Sex'].replace('male', 0, inplace=True)
train_df['Sex'].replace('female', 1, inplace=True)
Embarked는 원핫벡터로 나눈다.
1
2
3
train_df_embarked = pd.get_dummies(train_df['Embarked'])
train_df = pd.concat([train_df, train_df_embarked], axis=1)
train_df_embarked.head()
Ticket은 문자와 숫자로 구성되어있는데, 혹시 모르니 숫자만 분리해보자
1
2
3
4
import re
ticket_filter = r'(\d+$)'
train_df['Ticket'] = train_df['Ticket'].str.extract(ticket_filter)
train_df['Ticket'] = pd.to_numeric(train_df['Ticket'])
분류에 필요 없어 보이는 문자행을 없앤다.
1
train_df.drop(['Name', 'Cabin', 'Embarked'], axis=1, inplace=True)
상관계수 확인
1
train_df.corr()
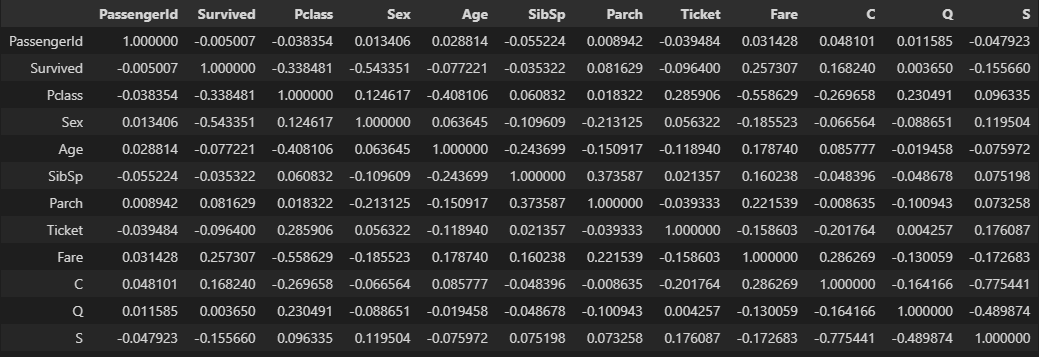 Pclass, 성별, 요금 정도가 생존과 관련 있어 보인다.
Pclass, 성별, 요금 정도가 생존과 관련 있어 보인다.
분류
데이터 분리
1
2
3
4
from sklearn.model_selection import train_test_split
X_data = train_df
y_data = train_df.pop('Survived')
X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, random_state=0)
정규화
1
2
3
4
5
6
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_train_scaled = pd.DataFrame(X_train_scaled, columns=X_data.columns)
X_test_scaled = scaler.transform(X_test)
X_test_scaled = pd.DataFrame(X_test_scaled, columns=X_data.columns)
결정트리
1
2
3
4
5
6
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier().fit(X_train_scaled, y_train)
print('Accuracy of Decision Tree classifier on training set: {:.3f}'
.format(clf.score(X_train_scaled, y_train)))
print('Accuracy of Decision Tree classifier on test set: {:.3f}'
.format(clf.score(X_test_scaled, y_test)))
Accuracy of Decision Tree classifier on training set: 1.000
Accuracy of Decision Tree classifier on training set: 0.838
끝으로
- MinMaxScaler랑 별 차이는 없는듯.
- Ticket은 숫자만 추출해봤지만, 큰 의미는 없었다.
- 중요한 데이터가 몇 개 없는 것을 보면 다른 알고리즘을 써도 비슷한 결과가 나올 것 같다.
- 내가 놓친 데이터가 있을 것 같은데..